Microservices is a popular and wide-spread architectural style for building non-trivial applications. They offer immense advantages but also some challenges and traps. Some obvious, some of a more insidious nature. In this brief article, I want to focus on how to integrate microservices.
This overview explains and compares common patterns for dealing with data in microservice architectures. I neither assume to be complete regarding approaches nor do I cover every pros and cons of each pattern. As always, experience and context matter.
Four different parts focus on different patterns.
- Sharing a database
- Synchronous calls
- Replication
- Event-driven architectures
The previous article looked at integrating microservices using one shared database. Sharing a database seems to be a straightforward approach. Even so, it led to architectural and organisational challenges.
In this part, we‘ll look at coupling microservices with synchronous calls. We’ll start by explaining the pattern itself. Then we’ll analyse technological and architectural aspects.
Synchronous Calls
Integrating microservices through synchronous calls is one of the more straightforward patterns. If a service A needs data owned by another service B, then A uses the API of B to get to whatever A needs.
The following image illustrates this pattern.

Two services serve as examples: one managing bank-accounts and one managing access-privileges. Let’s say a web application needs to fetch the bank-account overview. The web application sends a GET request to the bank-account service. The latter service replies with the overview data.
The bank-account service checks if the caller can view the requested data. The bank-account service sends a GET request to the access-privilege service. The access-privilege service checks the validity of the request and answers.
The actual communication protocol does not impact this discussion much. The arguments do not change whether we use REST, gRPC, or even SOAP.
Be aware that the actual protocol may worsen some implications. For example, by increasing the communication overhead. Concrete requirements and use cases should drive the selection of the protocol.
The advantages of reusing assets via API calls are clear.
The API protects its users from internal implementation details. Whether a service uses a SQL database or a graph database does not leak to its users. Even changes become easier. Changes to the internal data structure and logic do not impact users of the API. This allows for a more nuanced release strategy for additional features. Finally, API reuse does not require special middleware or infrastructure. It does not get easier than a HTTPS call.
I do not want to go into any detailed discussion around the advantages of great APIs. The internet provides lot’s of documentation on this topic.
Implications
Let’s have a look at the implications of coupling microservices in this way. We start with technical issues like availability and move to organisational aspects towards the end.
Testing
One more or less visible implication is the test setup. The tester needs to fulfil the dependency on the access privilege service.
It does not matter if we are running the service on a local machine or during an integration test. This requires either a complex setup running all services, e.g. with docker-compose. Or we could create a stub or mock using e.g. Mountebank for the downstream dependencies.
Both approaches lead to a higher risk of finding bugs and issues in later stages.
Availability
As shown, the bank-account service depends on the access-privilege service at runtime. Downtimes of the access-privilege service impact the bank-account service.
Graceful degradation is essential. Everything is better from a customer-perspective than a 503 error-page.
Consider the access-privilege service being up and running. But does not respond fast enough. The reasons could be many: some database hick-up, or network congestion. The following image illustrates this case. When sending a GET request, the bank-account runs into a timeout (TOUT).

There is no general best approach on how to deal with these scenarios. In case of idempotent requests, e.g. GET, then retrying the request may be an option. But even this may not be the case.
The access-privilege service may be under extraordinary stress. Retrying in this scenario will make things even worse. Google’s SRE book explains the different implications in detail.
Things get even more complicated if we take non-idempotent requests into account. Let’s look at a different use case. An actor wants to transfer money to some bank account, illustrated by the following image.

The actor uses the transaction (TRX) service (I) to execute a money transfer. The TRX service relies on a third party API for the actual money transfer (II). The third-party API replies with a successful response (III). Finally, the TRX service replies to the actor (IV).
But what happens, if things do not work as expected.
What happens if the connection from the actor to the TRX service gets dropped. The calling service has no idea whether or not the money transfer succeeded.
- Did the transfer service execute the request? Did it only fail to return a response to the calling service?
- Can we retry the money transfer without the risk of transferring the money twice?
This situation requires implementing extra orchestration and compensation logic. Service using business request ids can determine if it already served a money transfer request.
Latency
The following image illustrates the impact on latency.
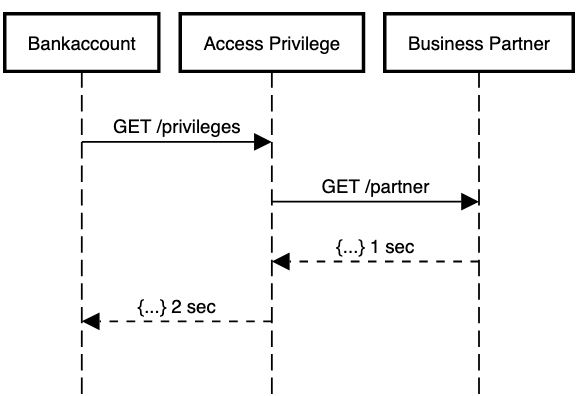
The bank-account service calls the access privilege service. The access privilege service calls the business partner service. The call between access and business partner takes 1 second. Bank-account sends the last reply after 2 seconds.
Now assume that the bank-account service should respond in 1,5 seconds. Here, the end-to-end example above will not meet that rule.
The access privilege service could skip the call to business partner service. It could return an error to the bank-account service instead. Passing a deadline from service to service may be one solution. The bank-account service passes an extra deadline parameter. The deadline parameter says: “Hey, access privilege service, you have 1 second to reply to my request. Otherwise, I don’t need an answer and won’t wait for an answer”.
The details don’t matter. The performance will suffer because of the communication overhead. Patterns or workarounds that deal with deadlines complicate service implementation.
Team Interlock
This implication is less technical, but organisational. Let’s consider an extended scenario, illustrated by the following image.

The bank-account and the access privilege services depend on a third service. This service provides business partner information. For example, first and last name, mail address, and so on. In principle this setup may work, keeping in mind the implications outlined above.
The more severe problem lies on the organisational level. Suppose different teams own each service, see the following illustration.
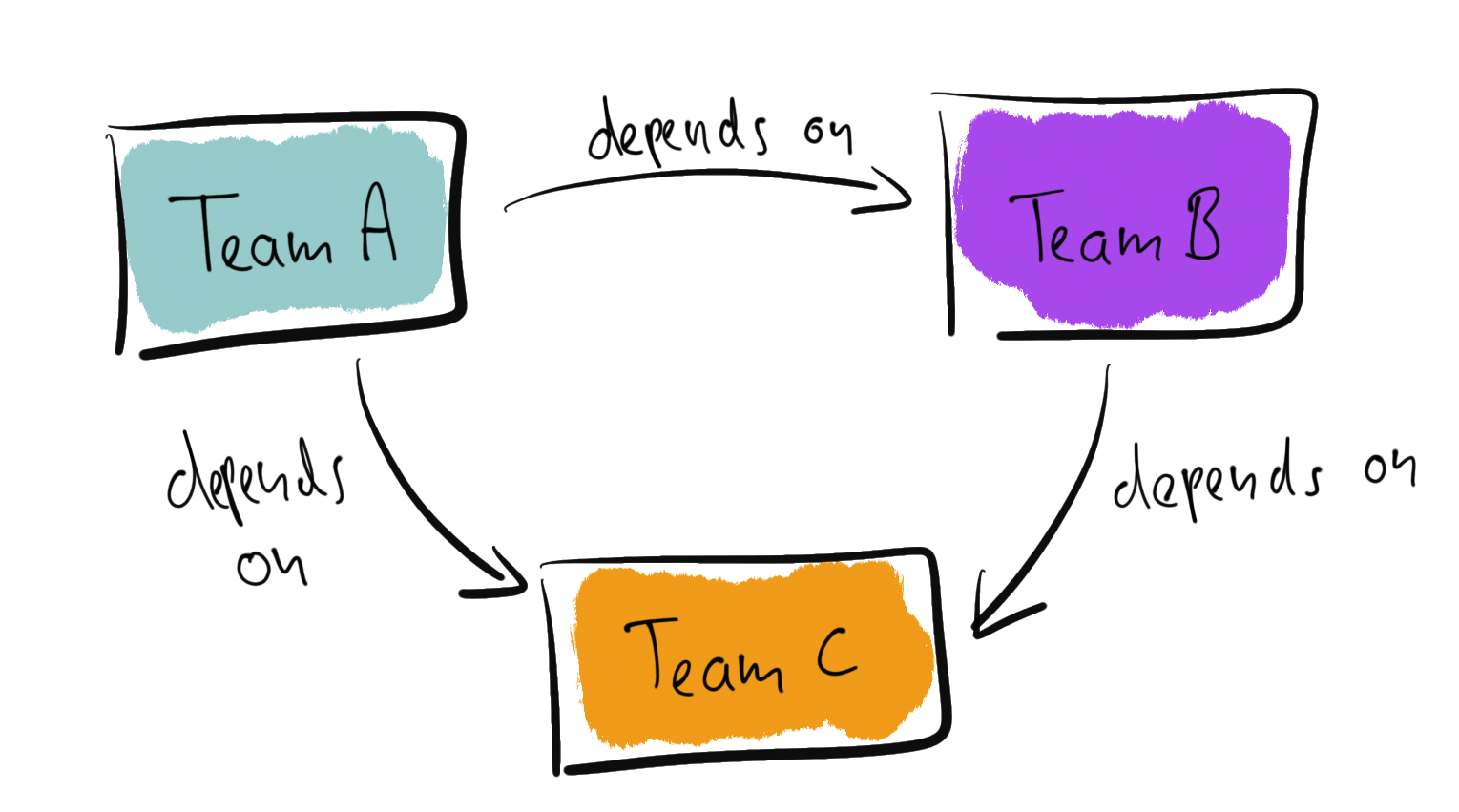
Team A and team B depend on team C. Looking at the relationship between the teams, the underlying challenge becomes obvious.
First, let’s consider a “customer/supplier” relationship. Team C provides a service for the other teams, and both team A and B can pass feature requests to team C.
In this scenario, team C may face a prioritisation problem. Should A or B get their requested feature first? What about conflicting requirements? What about versioning?
This can lead to very complicated management discussion and change management processes. Note that politics can and will play a role here. If the owner of C is more incentivised to support A than B then this may become problematic for team B. This boils down to bonuses or career moves.
Another interesting relationship is the “conformist”, where A and B have to take team C’s services as-is. This means both are at the mercy of team C. If team C changes the API for whatever reason, then team A and B have to conform to the new version. This introduces unplanned engineering effort into A and B. the risk for issues when deploying new versions into production increases.
These are only two examples, the relationships can be very complex. Vernon goes into extreme detail in his book about “Implementing Domain Driven Design”.
Release cascade
As a last implication, let’s consider the example with three services and three teams again.
Team A is in a problematic planning situation. The bank-account service depends on both of the other services. This means that team B and C must release before team A can release its service.
The following image illustrates this situation.

Team A finished their implementation in February. Yet, they have to postpone until May before they can continue with deployment. Team B also needs to wait for team C to finish its implementation. The release cascade becomes clear. This requires a high degree of planning alignment between the teams. Finger-pointing because of missed release dates can be one result.
Release trains are one method to cope with such temporal dependencies. Although this approach can work, it can also lead to a decrease in quality. If team C has to meet the deadline of April, they take short-cuts and skip testing.
Summary
Using synchronous calls to integrate microservices is a straightforward implementation pattern. Easy to put in place, debug, and analyse.
Yet, as we have seen, technical and organisational challenges - some obvious, some not so.
The reliability depends on timeout configurations and circuit breakers. Effective monitoring, alerting and clear service level objectives make life easier for everybody.
Graceful degradation can mitigate business impact. E.g. falling back to a locally cached variant or some default behaviour. The solution space depends on the business domain. The person owning the service must decide on the proper strategy.
The organisational implications are harder to tackle. Personal bias, politics, and money may impact the level of cooperation between teams. Especially if the teams cross project boundaries. For E.g. one team working on a new and shiny cloud service and the other maintains a not-so-shiny backend legacy service.
We should try to make these dependencies transparent. Especially the kind of relationship (conformist etc.) is very helpful. This can support dealing with such situations. Context-maps from Strategic-Domain-Driven-Design are one great tool to visualise this.
It is worth mentioning that the organisational challenges are the same for code and library reuse. If different teams own reused libraries, then the same questions need an answer.
If you want to dig deeper into these topics, then the following books are worth checking out:
- Site Reliability Engineering: How Google Runs Production Systems, by B. Beyer et. al.
- Release It!: Design and Deploy Production-Ready Software, by M. Nygard
- Implementing Domain-Driven Design, by V. Vernon
Pros
- easy to implement
- no direct dependency to persistence technology
- debugging and end-to-end monitoring possible
- dependencies are often explicit
Cons
- Latency and availability suffers
- Testing requires a more complex setup
- Release coordination and change management required
- Politics may make things harder
Outlook
The next article will look at data replication. Autonomous services, each relying on a local database. Data is replicated between the databases or some intermediary mechanism. This is the precursor to the final article, which tackles asynchronous events.